物理学者(ポスドク)による日々の研究生活のメモ書きです ( python/emacs/html/Japascript/シェルスクリプト/TeX/Mac/C言語/Linux/git/tmux/R/ポケモンGO)
次の3枚の画像を1枚の画像としてまとめたい
やり方は
1. Macのプレビューで全部開く -> 印刷画面 -> レイアウト -> ページ数/枚を4枚とかに変更 -> 左下のPDFボタンから画像出力する
2. montageコマンドを用いて1枚にする
1の方法は書いてある文章の通り
2の方法のコマンドはこんな感じ

 ■ コマンドの簡単な説明
■ コマンドの簡単な説明
-tileは何枚ずつ並べるかを指定できる
上のを見てもらうとわかるように [横に何枚か] x [縦に何枚か] で指定
*.pngというようにワイルドカードも使える
ワイルドカードを使わないなら、hoge1.png hoge2.png hoge3.pngのように並べて書く
1x3の場合は並べる画像のファイルを3つ指定した後のファイル名が出力ファイルになる
今回はhoge.png
-geometry 1080x720は出力する画像のサイズを決められる
入力画像のサイズは統一しておくと便利
また、画像のサイズを知りたいときはidentifyコマンドで
他にはImageMagic関連のconvertコマンドのメモは以下から
■ 過去記事 : 【convert】png画像からgif画像を作るには
ツイート
やり方は
1. Macのプレビューで全部開く -> 印刷画面 -> レイアウト -> ページ数/枚を4枚とかに変更 -> 左下のPDFボタンから画像出力する
2. montageコマンドを用いて1枚にする
1の方法は書いてある文章の通り
2の方法のコマンドはこんな感じ
montage -tile 3x1 -geometry 1080x720 *.png hoge_3x1.png
montage -tile 1x3 -geometry 1080x720 *.png hoge_1x3.png
montage -tile 3x2 -geometry 1080x720 *.png *.png hoge_3x2.png
■ コマンドの簡単な説明montage [オプション] 入力画像の名前(複数) 出力画像の名前
というのが使い方-tileは何枚ずつ並べるかを指定できる
上のを見てもらうとわかるように [横に何枚か] x [縦に何枚か] で指定
*.pngというようにワイルドカードも使える
ワイルドカードを使わないなら、hoge1.png hoge2.png hoge3.pngのように並べて書く
1x3の場合は並べる画像のファイルを3つ指定した後のファイル名が出力ファイルになる
今回はhoge.png
-geometry 1080x720は出力する画像のサイズを決められる
入力画像のサイズは統一しておくと便利
また、画像のサイズを知りたいときはidentifyコマンドで
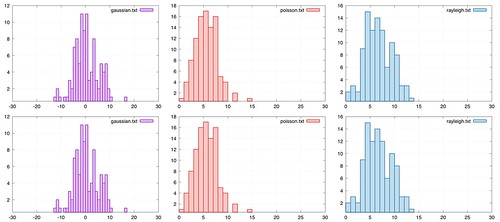
% identify rayleigh.png
rayleigh.png PNG 1080x720 1080x720+0+0 8-bit sRGB 22.6KB 0.000u 0:00.000
rayleigh.png PNG 1080x720 1080x720+0+0 8-bit sRGB 22.6KB 0.000u 0:00.000
他にはImageMagic関連のconvertコマンドのメモは以下から
■ 過去記事 : 【convert】png画像からgif画像を作るには
PR
こんな感じでOK
[ ]の中はすべて半角スペースで区切る
[ と !の間にスペース、$FILEのEと]の間のスペースを忘れるとエラーで怒られる
if [ ! -s $FILE ]; then
# ファイルサイズが0のとき
fi
# ファイルサイズが0のとき
fi
似たようなのでこんな記事もある
■ 参考 : 【シェルコマンド】ファイルサイズが0のファイルを削除する
よくアクセス解析をしてると、URLの中身が%に置き換わってたりして何書いてるのか全然わからないことがある・・・
そういうときは、以下のページに入力すると変換して見やすくなる
■ 参考サイト : URLエンコード・デコードフォーム
例として、この記事のURLは次のように変換される
http://coffee.guhaw.com/Entry/697/
↑
↓
http%3a%2f%2fcoffee%2eguhaw%2ecom%2fEntry%2f697%2f
↑
↓
http%3a%2f%2fcoffee%2eguhaw%2ecom%2fEntry%2f697%2f
ググったら、これはnkfコマンドとかを使えば同等のことができるっぽい
echo 'http://coffee.guhaw.com/Entry/697/' | nkf -WwMQ | tr = %
↓
http%3A%2F%2Fcoffee%2Eguhaw%2Ecom%2FEntry%2F697%2F
↓
http%3A%2F%2Fcoffee%2Eguhaw%2Ecom%2FEntry%2F697%2F
また、逆は、
echo 'http%3a%2F%2Fcoffee%2Eguhaw%2Ecom%2FEntry%2F697%2F' | nkf -w --url-input
↓
http://coffee.guhaw.com/Entry/697/
↓
http://coffee.guhaw.com/Entry/697/
condorに関する過去記事
■ 過去記事 : 【condor】について調べたのでメモ
■ 過去記事 : 【condor】shared libraryを使ったプログラムをジョブに渡すとき
condor_rmのヘルプを見るとタイトルと関係あるオプションを見つけてしまった
(スペースとタブが潰れたので見にくい・・・)
Usage: condor_rm [options] [constraints]
where [options] is zero or more of:
-help Display this message and exit
-version Display version information and exit
-long Display full result classad
-totals Display success/failure totals
-name schedd_name Connect to the given schedd
-pool hostname Use the given central manager to find daemons
-addr Connect directly to the given "sinful string"
-reason reason Use the given RemoveReason
-forcex Force the immediate local removal of jobs in the X state
(only affects jobs already being removed)
and where [constraints] is one of:
cluster.proc Remove the given job
cluster Remove the given cluster of jobs
user Remove all jobs owned by user
-constraint expr Remove all jobs matching the boolean expression
-all Remove all jobs (cannot be used with other constraints)
where [options] is zero or more of:
-help Display this message and exit
-version Display version information and exit
-long Display full result classad
-totals Display success/failure totals
-name schedd_name Connect to the given schedd
-pool hostname Use the given central manager to find daemons
-addr
-reason reason Use the given RemoveReason
-forcex Force the immediate local removal of jobs in the X state
(only affects jobs already being removed)
and where [constraints] is one of:
cluster.proc Remove the given job
cluster Remove the given cluster of jobs
user Remove all jobs owned by user
-constraint expr Remove all jobs matching the boolean expression
-all Remove all jobs (cannot be used with other constraints)
単体のジョブを消すときは、
condor_rm [ID]
自分が投下したジョブをすべて止めるときは、
condor_rm [user name]
または
condor_rm -all
または
condor_rm -all
condor_rm -constraint
で、条件文を書いてそれにmatchしたジョブだけを取り消せるらしいちなみに-constraintは-constと省略することもできるっぽい
条件文は、
condor_rm -const 'ClusterId > 3880'
な感じで書くcondor_qで表示されるジョブIDはClusterIdと呼ばれるらしい(CとIは大文字)
この変数名を探すのにかなり苦労したが、
condor_q -long | grep "3571"
みたいな感じで調べた
他にもやたら変数がセットされてるっぽいので、それらも使えるかもしれない(試してないけど)
sshログインしてたら、次のようなエラーがログイン時に表示されるようになった
/usr/bin/xauth: error in locking authority file /somewhere/.Xauthority
/somewhereは自分のホームディレクトリrm ~/.Xauthority-c
:> .Xauthority
chmod 600 ~/.Xauthority
で、エラーはでなくなった:> .Xauthority
chmod 600 ~/.Xauthority
何が原因で起こったんだ?
まずデータの紹介
これがhoge1.txt
hoge2.txtは$1が小数なのでhoge1.txtと同じ方法では重複を判別できない
ググったらまずは「uniqを使うんや」という知見を得たのでやってみた。
まずuniqコマンドの使い方は、
行全体の一致を調べてくれているので、この場合は役に立たない
アフォなのでパス
また、連続していない重複は消してくれないので
もし連続していない別の列との重複も消したい場合は事前にsortしておく必要がある
■ 参考 : uniq コマンド
googleで「sort 重複 -uniq」で調べたらやっと出てきた・・・
■ 参考 : ソートしないで重複行を削除する
説明は参考リンクにあるのでパス(正直わからんちん)
このコマンドをそのままこれそのまま打っても ! がダメっぽい
シェルスクリプトとかにすればいける?
一応、これでhoge1.txtの$1から重複してるものを取り除くことはできた
他の行の重複を調べたいときは$1を置き換えればOK
他には、$2が大きいものから残しているようにしたかったら
(2017/4/13 追記)
上記のソートで sort -k -r -nと書いていたけど、nオプションは整数を並べ替えるときに使うっぽい
符号を含んだ実数(+1e-5とか-1e-13)とかは-gオプションを付けてソートする
次にhoge2.txtの$1の整数部分を取り出してみる
これで、データを整数型にできれば、あとはhoge1.txtと同様にして重複部分を取り除けるわー
ツイート
これがhoge1.txt
3333 0.840188
4444 0.394383
1111 0.783099
1111 0.79844
3333 0.911647
3333 0.197551
4444 0.335223
これがhoge2.txt4444 0.394383
1111 0.783099
1111 0.79844
3333 0.911647
3333 0.197551
4444 0.335223
3333.0 0.840188
4444.2 0.394383
1111.1 0.783099
1111.2 0.79844
3333.0 0.911647
3333.5 0.197551
4444.9 0.335223
hoge1.txtは$1が整数だけど、4444.2 0.394383
1111.1 0.783099
1111.2 0.79844
3333.0 0.911647
3333.5 0.197551
4444.9 0.335223
hoge2.txtは$1が小数なのでhoge1.txtと同じ方法では重複を判別できない
ググったらまずは「uniqを使うんや」という知見を得たのでやってみた。
まずuniqコマンドの使い方は、
% uniq hoge1.txt
3333 0.840188
4444 0.394383
1111 0.783099
1111 0.79844
3333 0.911647
3333 0.197551
4444 0.335223
で、連続して重複した行を1つにまとめてくれるはずなのだが、3333 0.840188
4444 0.394383
1111 0.783099
1111 0.79844
3333 0.911647
3333 0.197551
4444 0.335223
行全体の一致を調べてくれているので、この場合は役に立たない
%uniq -c hoge1.txt
で、一致している行には数字を打ってくれる機能をうまく使えばなんとかできる気がしたけど、アフォなのでパス
また、連続していない重複は消してくれないので
もし連続していない別の列との重複も消したい場合は事前にsortしておく必要がある
■ 参考 : uniq コマンド
googleで「sort 重複 -uniq」で調べたらやっと出てきた・・・
■ 参考 : ソートしないで重複行を削除する
awk '!a[$0]++' FILE
でいいらしい説明は参考リンクにあるのでパス(正直わからんちん)
このコマンドをそのままこれそのまま打っても ! がダメっぽい
シェルスクリプトとかにすればいける?
% awk '\!a[$1]++' hoge1.txt
3333 0.840188
4444 0.394383
1111 0.783099
で、! をエスケープすればたぶんOK3333 0.840188
4444 0.394383
1111 0.783099
一応、これでhoge1.txtの$1から重複してるものを取り除くことはできた
他の行の重複を調べたいときは$1を置き換えればOK
他には、$2が大きいものから残しているようにしたかったら
% sort -k2 -r -g hoge1.txt | awk '\!a[$1]++'
3333 0.911647
1111 0.79844
4444 0.394383
ただし、$1の並び順はめちゃくちゃになるけど3333 0.911647
1111 0.79844
4444 0.394383
(2017/4/13 追記)
上記のソートで sort -k -r -nと書いていたけど、nオプションは整数を並べ替えるときに使うっぽい
符号を含んだ実数(+1e-5とか-1e-13)とかは-gオプションを付けてソートする
次にhoge2.txtの$1の整数部分を取り出してみる
% awk '{print int($1), $1, $2}' hoge2.txt
または
% awk '{printf "%d %f %f\n", $1, $1, $2}' hoge2.txt
1つめの方法を見つけたときに、ほほ〜と思ったけど、2つめのprintfでごり押した方が早かったわ・・・・または
% awk '{printf "%d %f %f\n", $1, $1, $2}' hoge2.txt
これで、データを整数型にできれば、あとはhoge1.txtと同様にして重複部分を取り除けるわー
■ 参考 : sedを使って複数ファイルの文字列を一気に置換する
find *.c | xargs sed -i "s/hoge/foo/g"
これで、今のディレクトリの .c で終わるファイルの中身で、hogeをfooに一括置き換えできる
sedの-iオプションはファイルを上書き保存するオプション
sedは便利だけどsとかgとか絶対に忘れるのでメモしておく・・・
シェルスクリプトでプログラムを走らせているときに、通し番号的なものを使うことがある
そのときi=1, 2, 3あたりで終わるものならいいけど、10を超えるとファイルの並び順がめちゃくちゃになって嫌になる・・・
そこで01, 02, 03, ...10, 11, ...みたいに通し番号を0埋めしてしまう
そのためにはprintfというコマンドが使えるらしい
% printf "%02d\n" 2
02
% printf "%02d\n" 10
10
02
% printf "%02d\n" 10
10
使い方はC言語のprintfとほとんど同じだろう
■ 過去記事 : 【シェルスクリプト】bcコマンド
まさかの5年前の記事
10進数を2進数に変換は bc コマンドで簡単にできるらしい
% echo "obase=10; ibase=2; 11111111" | bc
255
% echo "obase=2; ibase=10; 255" | bc
11111111
255
% echo "obase=2; ibase=10; 255" | bc
11111111
ibaseが入力の数字が何進数か、obaseは出力の数字が何進数かを表す
(iはinput、oはoutputだと思う)
あとはbcの通常の使い方のように、それをechoしてパイプでbcに渡すだけ
■ 参考記事 : bcコマンドで16進数、10進数、8進数、2進数の変換・計算を行う方法
こんな記事を見つけた
■ 参考 : grepってオワコンだったの…
ackについてわかりやすい記事があったのでメモ
■ 参考 : ackを使おう!
これを見た感じでは、SVNのバージョン管理ソフトで真価を発揮するコマンドなのかな・・・という印象
試してみたら、Macにはデフォルトで入っていなかった・・・
portにはあった
ack @2.140.0_2 (devel)
A grep replacement, optimized for programmers
A grep replacement, optimized for programmers
まぁ使わん・・・・
あと、agってのもあるみたい
そっちもgitとかバージョン管理向けのコマンドっぽい
自分はそういう検索をしたいときは
find somewhere -name "*.c" | xargs grep "!*" --color
とかしてるわ・・・たぶんgrep使ってるから上記のack, agの方が早いんだろうな・・・
【シェルコマンド】lsでArgument list too long.というエラー (引数リストが長すぎます: rm)
2016.12.28 Wed 10:29 | シェルコマンド / シェルスクリプト
2016.12.28 Wed 10:29 | シェルコマンド / シェルスクリプト
ちょい前にlsしてたら、次のようなエラーが出てきた
ファイル数は確か18000くらい?
回避方法としては、
ちなみに不要ファイルを削除して、回避しようにもrmで同じエラーが出るので対処できない・・・
(2017/05/31 追記)
findを使っているのは単純にlsではファイル数が多すぎるとエラーが出るため
2番目の例では-eを2つ並べている
3番目の例では-veオプションを使っている
これはeオプションの否定になる
つまりfooもaaaaもファイル名に入っていないファイルがリストされる
正規表現を使いこなしていない自分にはかなり便利
(2023/04/23 追記)
また遭遇したので追記
ツイート
Argument list too long.
そのエラーでググってみたら、これはファイル数が多すぎるときに出るエラーらしいファイル数は確か18000くらい?
回避方法としては、
find . -name \*.log | xargs ls -l
とか
find . -name \*.log -exec ls -l {} \;
どっちもかなり遅かった気がする・・・・とか
find . -name \*.log -exec ls -l {} \;
ちなみに不要ファイルを削除して、回避しようにもrmで同じエラーが出るので対処できない・・・
ls -Ul
なら動く、という記事を見つけたが試してないので本当にlsできるかは不明(2017/05/31 追記)
find ./result/* -name "hoge*" | grep -e "foo" > hoge.txt
find ./result/* -name "hoge*" | grep -e "foo" -e "aaaa" > hoge.txt
find ./result/* -name "hoge*" | grep -ve "foo" -ve "aaaa" > hoge.txt
みたいにしてgrep -eを使ってさらにファイルを絞ることもできるfind ./result/* -name "hoge*" | grep -e "foo" -e "aaaa" > hoge.txt
find ./result/* -name "hoge*" | grep -ve "foo" -ve "aaaa" > hoge.txt
findを使っているのは単純にlsではファイル数が多すぎるとエラーが出るため
2番目の例では-eを2つ並べている
3番目の例では-veオプションを使っている
これはeオプションの否定になる
つまりfooもaaaaもファイル名に入っていないファイルがリストされる
正規表現を使いこなしていない自分にはかなり便利
(2023/04/23 追記)
また遭遇したので追記
echo ~/somewhere/* | xargs rm -f
awk '{print $0}' hoge.txt
これが基本の形ダブルコーテーションではなく、シングルコーテーションを使うこと
ダブルコーテーションを無理して使う場合は
awk "{print \$0}" hoge.txt
のようにエスケープすることこれを踏まえて、シェル変数をawkの中で使う場合は、
x=10
awk "{print \$0, $x}" hoge.txt
とかで使えるawk "{print \$0, $x}" hoge.txt
今日新しく知ったのが、そんなことをしなくてもシェル変数を渡すオプションがあった・・・
x=10
y=20
awk -v x=$x -v y=$y '{print $0, x, y}' hoge.txt
-vを何度も書けば複数のシェル変数を渡せるy=20
awk -v x=$x -v y=$y '{print $0, x, y}' hoge.txt
はぁ〜便利・・・
■ 参考 : awkからシェル変数を参照する
許可なしで削除するには
find ./ -size 0 -exec rm {} \;
許可を出してから削除するには
find ./ -size 0 -ok rm {} \;
まずはデータ生成
これもawkでやってしまおう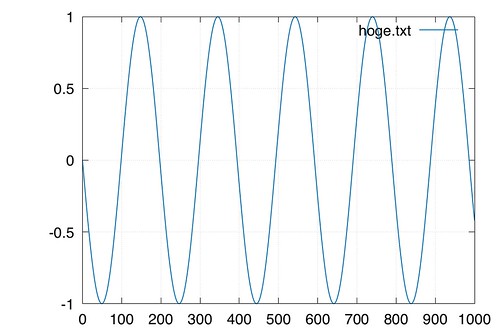
このデータの最大値を求めるには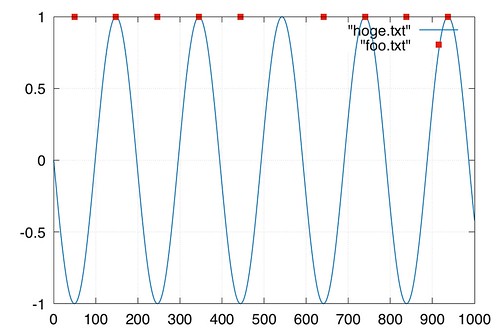
赤い時刻が極大値または極小値
もしそれらをバラバラに知りたかったら
awk 'NR==1{x=0} NR>1 {diff1=diff2; diff2=$2-x; x=$2} {if(diff1*diff2<0 && diff1>0)print $1, 1}' hoge.txt > maximum.txt
awk 'NR==1{x=0} NR>1 {diff1=diff2; diff2=$2-x; x=$2} {if(diff1*diff2<0 && diff1 <0) print $1,-1 }' hoge.txt > minimum.txtでおk
プロットは
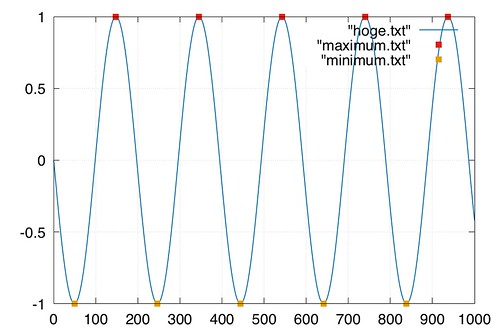
(本当はNR==1のときにdiff2=0ってした方がいい気がするけどまぁいいや・・・)
ツイート
これもawkでやってしまおう
awk 'BEGIN{fs=10.0;for (i = 0; i < 10000; i++){t=i/fs; print t, sin(2*3.14*t*10)}}' > hoge.txt
# もっと桁数が欲しい場合は
# ちなみに後述のawkコマンドを走らせてきちんと結果を得るためには桁数が必要なので、こっちで
awk 'BEGIN{fs=10.0;for (i = 0; i < 10000; i++){t=i/fs; printf "%.10e %.10e\n", t, sin(2*3.14*t*10)}}' > hoge.txt
# もっと桁数が欲しい場合は
# ちなみに後述のawkコマンドを走らせてきちんと結果を得るためには桁数が必要なので、こっちで
awk 'BEGIN{fs=10.0;for (i = 0; i < 10000; i++){t=i/fs; printf "%.10e %.10e\n", t, sin(2*3.14*t*10)}}' > hoge.txt
このデータの最大値を求めるには
awk 'NR==1 {max=$1} {if($1 > max) max = $1} END {print max}' hoge.txt
最小値は、awk 'NR==1 {min=$1} {if($1 < min) min = $1} END {print min}' hoge.txt
極大値、極小値を求めるにはawk 'NR==1{x=0} NR>1 {diff1=diff2; diff2=$2-x; x=$2} {if(diff1*diff2<0)print $1}' hoge.txt > foo.txt
これらを重ねてプロットしてみるplot "hoge.txt" w l lw 2 lc 6, "foo.txt" w p pt 5 ps 2 lc 7
赤い時刻が極大値または極小値
もしそれらをバラバラに知りたかったら
awk 'NR==1{x=0} NR>1 {diff1=diff2; diff2=$2-x; x=$2} {if(diff1*diff2<0 && diff1>0)print $1, 1}' hoge.txt > maximum.txt
awk 'NR==1{x=0} NR>1 {diff1=diff2; diff2=$2-x; x=$2} {if(diff1*diff2<0 && diff1 <0) print $1,-1 }' hoge.txt > minimum.txt
プロットは
plot "hoge.txt" w l lw 2 lc 6, "maximum.txt" w p pt 5 ps 2 lc 7, "minimum.txt" w p pt 5 ps 2 lc 4
で(本当はNR==1のときにdiff2=0ってした方がいい気がするけどまぁいいや・・・)
データを読み込んで、ある列とある列を掛算して、ファクターかけたりするのに、
わざわざコンパイルするほどのことでもないかなぁ〜と思って最近はawkを使うことがよくある
たぶんコンパイルした方が実行速度も早いけど、コードを書いて、makefileを用意して、さらにそれらをぶん回すシェルスクリプトを書くなら
最初からシェルスクリプトでawkを1行書いた方が早く終わりそう・・・・
もちろんシェルスクリプトに書かずにawk用のスクリプトを用意して
awk -f hoge.awk
とかで食わせるのもありだと思う・・・たぶんそうする利点は、awkファイル特有のインデントなどをきちんと使えるとか?知らんけど
話をタイトルに戻して、
awkで累乗の計算は
2**2
とかでいいらしいgnuplotと同じ方式だ・・・
ハット(^)を使うことはないだろうと思ってたが、powでもなくて**だったとは・・・
if文は本当にC言語とまんま同じ書き方でOK
あとは省略
そういえば・・・と思い立って調べてみた
シェルスクリプトで自作関数を定義して、それを何度も呼び出すことでコードの省略化が計れる
実際に書き方を調べてみたら、本当に簡単で、なおかつその効果は絶大・・・
もっと早くに出逢っていれば・・・・
■ 関数定義の仕方
#!/bin/sh
function hoge() {
# something
}
function hoge() {
# something
}
hogeは関数名なので、何か適当に置き換える
C言語の型変数みたいにfunctionと付いているのは関数定義のルールらしい
が、別に省略してもいいらしい
あと関数名の後の()は忘れがちなので注意
どういう引数が必要かは特に書く必要はない
引数の引用時には関数の中で
#!/bin/sh
function hoge() {
argv1=$1
argv2=$2
# something
}
# これは関数を呼び出しているところ
hoge rapu kabi
みたいにして、$1, $2と関数の引数を使用するfunction hoge() {
argv1=$1
argv2=$2
# something
}
# これは関数を呼び出しているところ
hoge rapu kabi
(シェルスクリプトの引数と同様、ということは$#や$@、$*などの変数もあるのか? いや、別に使わんからいいけど・・・)
(調べてみたらあるらしい)
関数を呼び出すときは()は不要
返り値も使用できるらしいけど、基本的にそういう凝った使い方をシェルスクリプトではしないので省略
基本的にプロットをfor i in `ls *.txt`とかで回したりするくらいなので・・・
あと実際に関数を書いてみて気づいたけど、
たぶん関数宣言と関数呼び出しの順番は、先に関数宣言をされていないとダメっぽい
(シェルスクリプトって上から順番に実行していくだけなのでそりゃあそうだと思うけど、そのことについて書かれてなかったのでちょっとハマった)
ここのフローチャートが割と参考になった
■ 参考 : フロー図を描いてみる
一応フローチャートを作るときの記号などは基本的なものに従ったつもりだけど、ちょっと違うかも・・・
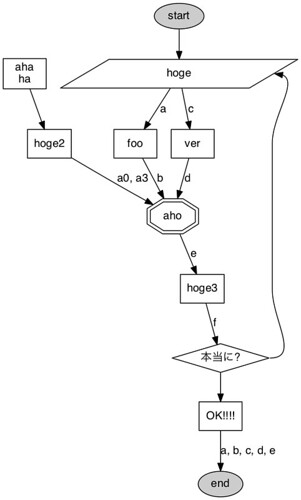
digraph flowchart {
node [shape="box", fontname="MS Gothic"];
edge [fontname="MS Gothic"];
start [label="start", shape="ellipse", style="filled", fillcolor="#CCCCCC", width=0.1, height=0.1];
end [label="end", shape="ellipse", style="filled", fillcolor="#CCCCCC", width=0.1, height=0.1];
node5 -> node6;
node6 -> node3[label="a0, a3"];
start -> node1;
node1 -> node2[label="a"];
node2 -> node3[label="b"];
node1 -> node4[label="c"];
node4 -> node3[label="d"];
node3 -> node7[label="e"];
node7 -> node8[label="f"];
node8 -> node9;
node9 -> end[label="a, b, c, d, e"];
node8 -> node1[tailport=e, headport=e];
node1 [label="hoge", shape="parallelogram", fixedsize="true", width=4.0, height=0.5];
node2 [label="foo"];
node3 [label="aho", shape="doubleoctagon"];
node4 [label="ver"];
node5 [label="aha\nha"];
node6 [label="hoge2"];
node7 [label="hoge3"];
node8 [label="本当に?", shape="diamond"];
node9 [label="OK!!!!"];
}
node [shape="box", fontname="MS Gothic"];
edge [fontname="MS Gothic"];
start [label="start", shape="ellipse", style="filled", fillcolor="#CCCCCC", width=0.1, height=0.1];
end [label="end", shape="ellipse", style="filled", fillcolor="#CCCCCC", width=0.1, height=0.1];
node5 -> node6;
node6 -> node3[label="a0, a3"];
start -> node1;
node1 -> node2[label="a"];
node2 -> node3[label="b"];
node1 -> node4[label="c"];
node4 -> node3[label="d"];
node3 -> node7[label="e"];
node7 -> node8[label="f"];
node8 -> node9;
node9 -> end[label="a, b, c, d, e"];
node8 -> node1[tailport=e, headport=e];
node1 [label="hoge", shape="parallelogram", fixedsize="true", width=4.0, height=0.5];
node2 [label="foo"];
node3 [label="aho", shape="doubleoctagon"];
node4 [label="ver"];
node5 [label="aha\nha"];
node6 [label="hoge2"];
node7 [label="hoge3"];
node8 [label="本当に?", shape="diamond"];
node9 [label="OK!!!!"];
}
そのうち色々と追記して行きます
わかりやすい参考記事
■ 参考 : DOTユーザーズガイドの日本語訳
■ 参考 : Graphvizとdot言語でグラフを描く方法のまとめ
■ 疑問
・数式は入れることができないのか?
日本語はそのまま入力できるし、表示もされる
コメント文
矢印なしのフローチャート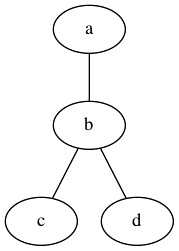 矢印ありのフローチャート
矢印ありのフローチャート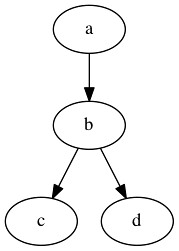
wikiの一番下にあった問題点ってのをそのままコピーして作ってみたら
グニャ〜って曲がったグラフができた・・・ 失敗だ・・・
digraph g {
node [shape=plaintext]
A1 -> B1
A2 -> B2
A3 -> B3
A1 -> A2 [label=f]
A2 -> A3 [label=g]
B2 -> B3 [label="g'"]
B1 -> B3 [label="(g o f)'" tailport=s headport=s]
{ rank=same; A1 A2 A3 }
{ rank=same; B1 B2 B3 }
}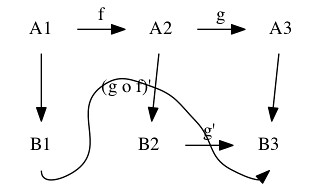
「上から下に」じゃなくて「左から右に」進むフローチャートができる
色を付ける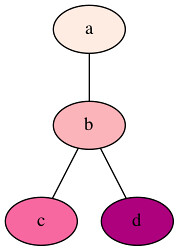 node [style=filled, colorscheme=rdpu3];の行は上の方に書かないとエラーが出た
node [style=filled, colorscheme=rdpu3];の行は上の方に書かないとエラーが出た
調べてないから勘だけど、rdpu4の数字はいじってもOK
ある色からある色までを4分割するってことだと思う
数字を4にしたままで
d [style=filled, fillcolor=5];
のように置き換えるとエラーが出て変な色で塗りつぶされる
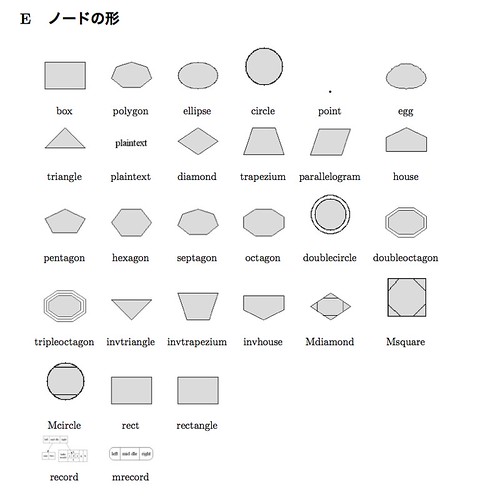
ノードの形は以下のような種類がある(参考にしたpdfより)
■ 文字を改行したい
■ 矢印の横に文字を入れる方法
同じく一つ上のスクリプトで
たぶん、フローチャートの形によっては矢印と干渉するのでスペースなどを入れて対処する
他にも、次のようなオプションが付けられる。
shapeの中には「レコード」というものがある
縦横に自由に分割できる上に、分割したパートについても矢印の出し入れができる
■ 接続ポート
それぞれのノードの左右上下どこから矢印を出すかを制御できる
 headport="w"のようにダブルコーテーションはいらないので注意
headport="w"のようにダブルコーテーションはいらないので注意
逆にtailportつまりaから出るところは右から出るようになっている
(矢印にとってのheadとtailなので少し理解するのに苦労した・・・)
■ 次へ : 【dot言語】フローチャートを1つ書いてみた
ツイート
わかりやすい参考記事
■ 参考 : DOTユーザーズガイドの日本語訳
■ 参考 : Graphvizとdot言語でグラフを描く方法のまとめ
■ 疑問
・数式は入れることができないのか?
日本語はそのまま入力できるし、表示もされる
コメント文
// ここはコメント文
/* ここはコメント文 */
# ここはコメント文
の3種類がある/* ここはコメント文 */
# ここはコメント文
矢印なしのフローチャート
graph graphname {
a -- b -- c;
b -- d;
}
a -- b -- c;
b -- d;
}
矢印ありのフローチャートdigraph graphname {
a -> b -> c;
b -> d;
}
a -> b -> c;
b -> d;
}
wikiの一番下にあった問題点ってのをそのままコピーして作ってみたら
グニャ〜って曲がったグラフができた・・・ 失敗だ・・・
digraph g {
node [shape=plaintext]
A1 -> B1
A2 -> B2
A3 -> B3
A1 -> A2 [label=f]
A2 -> A3 [label=g]
B2 -> B3 [label="g'"]
B1 -> B3 [label="(g o f)'" tailport=s headport=s]
{ rank=same; A1 A2 A3 }
{ rank=same; B1 B2 B3 }
}
rankdir=LR;
とスクリプトファイルの中に書いておくと「上から下に」じゃなくて「左から右に」進むフローチャートができる
色を付ける
graph graphname {
node [style=filled, colorscheme=rdpu4];
#rankdir=LR;
a -- b -- c;
b -- d;
a [style=filled, fillcolor=1];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
node [style=filled, colorscheme=rdpu4];
#rankdir=LR;
a -- b -- c;
b -- d;
a [style=filled, fillcolor=1];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
node [style=filled, colorscheme=rdpu3];の行は上の方に書かないとエラーが出た調べてないから勘だけど、rdpu4の数字はいじってもOK
ある色からある色までを4分割するってことだと思う
数字を4にしたままで
d [style=filled, fillcolor=5];
のように置き換えるとエラーが出て変な色で塗りつぶされる
ノードの形は以下のような種類がある(参考にしたpdfより)
graph graphname {
node [style=filled, colorscheme=rdpu4];
#rankdir=LR;
a -- b -- c;
b -- d;
a [style=filled, fillcolor=1, share=circle];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
のようにcircleと書けば円になってくれるnode [style=filled, colorscheme=rdpu4];
#rankdir=LR;
a -- b -- c;
b -- d;
a [style=filled, fillcolor=1, share=circle];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
■ 文字を改行したい
\n
でおk■ 矢印の横に文字を入れる方法
同じく一つ上のスクリプトで
b -- d[label="hoge"];
のようにすればhogeと入るたぶん、フローチャートの形によっては矢印と干渉するのでスペースなどを入れて対処する
他にも、次のようなオプションが付けられる。
// edge define
alpha -> beta [
label = "a-b", //エッジラベル
labelfloat = true, //ラベルの重なりを許可する
headlabel = "head", //エッジの終端にラベルをつける
taillabel = "tail", //エッジの始端にラベルをつける
labeldistance = 2.5, //ラベルの位置をノードからの距離で指定する
labelangle = 70, //ラベルの位置を角度で指定する
color = blue, //エッジカラー
style = solid, //エッジスタイル
dir = both, //エッジの矢印を指定する
arrowhead = normal, //エッジの終端の形状を指定
arrowtail = normal, //エッジの始端の形状を指定
arrowsize = 1, //矢印の大きさ倍率で指定
weight = 5 //エッジの重み付け 重みが大きいエッジが結ぶノードがより近く配置される
fontname = "Migu 1M", //エッジラベルフォント
fontsize = 14, //エッジラベルフォントサイズ
fontcolor = blue //エッジラベルフォントカラー
];
■ 参考 : Graphvizとdot言語でグラフを描く方法のまとめalpha -> beta [
label = "a-b", //エッジラベル
labelfloat = true, //ラベルの重なりを許可する
headlabel = "head", //エッジの終端にラベルをつける
taillabel = "tail", //エッジの始端にラベルをつける
labeldistance = 2.5, //ラベルの位置をノードからの距離で指定する
labelangle = 70, //ラベルの位置を角度で指定する
color = blue, //エッジカラー
style = solid, //エッジスタイル
dir = both, //エッジの矢印を指定する
arrowhead = normal, //エッジの終端の形状を指定
arrowtail = normal, //エッジの始端の形状を指定
arrowsize = 1, //矢印の大きさ倍率で指定
weight = 5 //エッジの重み付け 重みが大きいエッジが結ぶノードがより近く配置される
fontname = "Migu 1M", //エッジラベルフォント
fontsize = 14, //エッジラベルフォントサイズ
fontcolor = blue //エッジラベルフォントカラー
];
shapeの中には「レコード」というものがある
縦横に自由に分割できる上に、分割したパートについても矢印の出し入れができる
■ 接続ポート
それぞれのノードの左右上下どこから矢印を出すかを制御できる
n : 上
ne : 右上
e : 右
se : 右下
s : 下
sw : 左下
w : 左
nw : 左上
c : 中央
_ : 自動
ne : 右上
e : 右
se : 右下
s : 下
sw : 左下
w : 左
nw : 左上
c : 中央
_ : 自動
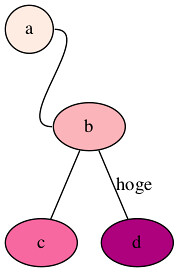
graph graphname {
node [style=filled, colorscheme=rdpu4];
a -- b[headport=w, tailport=e];
b -- c;
b -- d[label="hoge"];
a [style=filled, fillcolor=1, shape=circle];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
でnode [style=filled, colorscheme=rdpu4];
a -- b[headport=w, tailport=e];
b -- c;
b -- d[label="hoge"];
a [style=filled, fillcolor=1, shape=circle];
b [style=filled, fillcolor=2];
c [style=filled, fillcolor=3];
d [style=filled, fillcolor=4];
}
headport="w"のようにダブルコーテーションはいらないので注意a -- b[headport=w, tailport=e];
aからbへの矢印のうち、headportつまりbに入るところは左から逆にtailportつまりaから出るところは右から出るようになっている
(矢印にとってのheadとtailなので少し理解するのに苦労した・・・)
■ 次へ : 【dot言語】フローチャートを1つ書いてみた
dotというフローチャートを描くためのツールがある
doxygenというコードのドキュメントを自動生成するツールでも、このツールが使われていて
ある関数が別のコードのどの関数で呼ばれているかなどが視覚的にかなりわかりやすく描かれていたりする
インストールは
どんなことができるかは次のページを見てもらうとわかりやすいかも
■ 参考 : データのビジュアル化を最少の労力で
まずはdotに食わせるスクリプトファイルを用意する
hoge.dotというファイル名で以下の内容のもとを作成する
 手元で試したところ、gif, pdf, pngはできた
手元で試したところ、gif, pdf, pngはできた
他のフォーマットはあんまり使うことがないのでこれだけできれば十分か
ちょっと描きたいフローチャートがあるので、それが作る過程でいろいろと構文のことを勉強できるだろう
■ 次へ : 【dot言語】のチートシート
ツイート
doxygenというコードのドキュメントを自動生成するツールでも、このツールが使われていて
ある関数が別のコードのどの関数で呼ばれているかなどが視覚的にかなりわかりやすく描かれていたりする
インストールは
sudo port install graphviz
でOKどんなことができるかは次のページを見てもらうとわかりやすいかも
■ 参考 : データのビジュアル化を最少の労力で
まずはdotに食わせるスクリプトファイルを用意する
hoge.dotというファイル名で以下の内容のもとを作成する
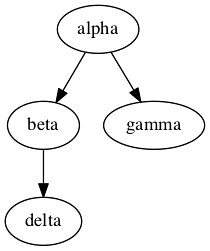
digraph sample {
alpha -> beta;
alpha -> gamma;
beta -> delta;
}
グラフとして出力するコマンドはalpha -> beta;
alpha -> gamma;
beta -> delta;
}
# dot -T[出力形式] [スクリプトファイル名] -o [出力ファイル名]
dot -Tpng hoge.dot -o hoge.png<.div>
これでできたのがdot -Tpng hoge.dot -o hoge.png<.div>
手元で試したところ、gif, pdf, pngはできた他のフォーマットはあんまり使うことがないのでこれだけできれば十分か
ちょっと描きたいフローチャートがあるので、それが作る過程でいろいろと構文のことを勉強できるだろう
■ 次へ : 【dot言語】のチートシート
■ 参考 : シェルスクリプトでコマンドの有無を確かめる
シェルスクリプトのifはこんなに使っても全然覚えられない・・・
testとifと[ ]があって頭グチャグチャ
whichの代わりに、hashやtypeというコマンドに置き換えても動くしそっちの方が早いという記事もあって試してみた
■ 参考 : Bashでコマンドの存在チェック
ツイート
if [ `which hoge` ]; then
echo 'hoge atta'
fi
自分も最初にwhichとifでどうにかなりそう・・・と思ったけど、if文の書き方がわからなくてググった・・・echo 'hoge atta'
fi
シェルスクリプトのifはこんなに使っても全然覚えられない・・・
testとifと[ ]があって頭グチャグチャ
whichの代わりに、hashやtypeというコマンドに置き換えても動くしそっちの方が早いという記事もあって試してみた
■ 参考 : Bashでコマンドの存在チェック
if type "hoge" > /dev/null 2>&1
then
echo "hoge atta"
fi
then
echo "hoge atta"
fi
デフォルトのdiffが見にくいので、--colorとかないのかな〜と思ってググったら色々と便利そうな情報が見つかった
■ 参考 : diff コマンド見辛かった
早速colordiff入れたわ・・・
あとは
-uオプションで、+/-とかで追記・削除などを表してくれるようになる
-yオプションで、真横に並べてくれる
このままでは見にくいので
% diff hoge.c foo.c -y > hoge.txt
% emacs hoge.txt
とかでOK?
あと
■ 参考 : diffの結果をカラーで閲覧
に書いてあったが、git repository内ならそもそもgit diffでcolor表示にできる
自分のコードのバグでオプション名の画像を作成してしまった・・・・
rm -x10:1590.png
ではオプションとして認識されて削除できないrm "-x10:1590.png"
rm '-x10:1590.png'
とか試したけどダメrm '-x10:1590.png'
ググったら2通りの解決方法が見つかった
rm ./-x10:1590.png
rm -- -x10:1590.png
rm -- -x10:1590.png
前者のは頑張れば気づきそうだったが、ダメだった
grep -r "hoge" *.c
とかやりたかったけど、できないっぽいので、解決方法を探したら見つかったfind ./ -name '*.c' | xargs grep "hoge" --color
*.cの中からhogeを全文検索
最後の--colorは色を付けてるだけ
プロフィール
HN:coffee
職業:物理屋(自称)
趣味:映画鑑賞、登山
出身:大阪府の南の田舎
自己紹介:
import MyProfile
import coffee_pote from TWITTER
import amazonのほしい物リスト from WISH_LIST
print "先月子供が産まれました!"
# 最終更新 2022/10/25
職業:物理屋
趣味:映画鑑賞、登山
出身:大阪府の南の田舎
自己紹介:
import MyProfile
import coffee_pote from TWITTER
import amazonのほしい物リスト from WISH_LIST
print "先月子供が産まれました!"
# 最終更新 2022/10/25
カウンター
カテゴリー
ブログ内検索
リンク
相互リンク募集中です
(Twitterにてお知らせください)
Demo scripts for gnuplot version 5 (gnuplotのさまざまなデモ画像と作り方がまとめられている、眺めているだけでできるようになった気分になれる)
gnuplotスクリプトの解説 (米澤進吾さんの個人ページ、gnuplotと言えばこのかた)
gnuplot のページ (Takeno Lab、うちのブログがリンクされていたのでリンク返し)
Twitterから映画の評価が分かる & 映画の鑑賞記録が残せる coco (映画の感想をまとめられるサイト、いつもお世話になっています)
Astronomy Picture of the Day Archive (天文や宇宙関連の最新の話題について画像とともにNASAが説明しているページ)
今日のほしぞら (任意の時刻の空で見える星を表示してくれる、国立天文台が管理している)
GNUPLOTとアニメーション (応用の項目の「見せてあげよう!ラピュタの雷を!!」あたりからすごすぎる)
読書メーター (読んだ本をリストできる便利なサイト)
flickr難民の写真置き場 (20XX年、flickrは有料化の炎に包まれた。あらゆるflickr無料ユーザーは絶滅したかに見えた。 しかし、tumblr移住民は死に絶えてはいなかった。)
教授でもできるMac OS X へのLaTeX, X11, gccのインストレーションと環境設定 (阪大の山中卓さんのwebページ、タイトルにセンスが溢れている、内容は超充実してる、特にTeX関連、学振DCとかPDの申請書類作成時にはお世話になっております)
英語論文執筆用の例文検索サービス (とんでもないものを見つけてしまった・・・・ arXivに収録されている 811,761報の 英語論文から,例文を検索するための検索エンジン)


Demo scripts for gnuplot version 5 (gnuplotのさまざまなデモ画像と作り方がまとめられている、眺めているだけでできるようになった気分になれる)
gnuplotスクリプトの解説 (米澤進吾さんの個人ページ、gnuplotと言えばこのかた)
gnuplot のページ (Takeno Lab、うちのブログがリンクされていたのでリンク返し)
Twitterから映画の評価が分かる & 映画の鑑賞記録が残せる coco (映画の感想をまとめられるサイト、いつもお世話になっています)
Astronomy Picture of the Day Archive (天文や宇宙関連の最新の話題について画像とともにNASAが説明しているページ)
今日のほしぞら (任意の時刻の空で見える星を表示してくれる、国立天文台が管理している)
GNUPLOTとアニメーション (応用の項目の「見せてあげよう!ラピュタの雷を!!」あたりからすごすぎる)
読書メーター (読んだ本をリストできる便利なサイト)
flickr難民の写真置き場 (20XX年、flickrは有料化の炎に包まれた。あらゆるflickr無料ユーザーは絶滅したかに見えた。 しかし、tumblr移住民は死に絶えてはいなかった。)
教授でもできるMac OS X へのLaTeX, X11, gccのインストレーションと環境設定 (阪大の山中卓さんのwebページ、タイトルにセンスが溢れている、内容は超充実してる、特にTeX関連、学振DCとかPDの申請書類作成時にはお世話になっております)
英語論文執筆用の例文検索サービス (とんでもないものを見つけてしまった・・・・ arXivに収録されている 811,761報の 英語論文から,例文を検索するための検索エンジン)
最新記事
(11/20)
(03/05)
(02/29)
(02/21)
(02/21)
(02/21)
(02/21)
(01/13)
(01/05)
(01/05)